Was versteht man unter einem pädagogischen Test?
Allgemein versteht man in der Alltagssprache unter einem Test ein mehr oder minder ausgefeiltes Prüfverfahren. Publikumszeitschriften veröffentlichen Fragebögen als „Tests“ zur Selbsterkenntnis oder Produkttests, die keine Tests im engeren Sinne darstellen, denn sie haben keine klar definierten Ziele, sie verwenden keine geprüften und oft nicht einmal einsehbare und nachvollziehbare Methoden und sie geben nicht an, auf Grundlage welcher Vergleichsdaten Bewertungen vorgenommen wurden.
Bei Blutzucker- oder Schwangerschaftstests, die es in der Apotheke zu kaufen gibt, ist das anders: Sie verfolgen klar definierte Ziele, etwa die Messung des Blutzuckerspiegels oder eines bestimmten Hormons. Zu diesem Zweck schreiben sie Verfahren zur Gewinnung, Analyse und Bewertung einer Stichprobe von Blut oder Urin vor. Sie verlangen ein systematisches Vorgehen gemäß einer detailliert vorgegebenen Handlungsanweisung, verwenden spezielle Mittel zur Analyse der Stichproben und stellen sorgfältig geprüfte Vergleichsdaten zur Bewertung der Ergebnisse zur Verfügung. Nur bei Einhaltung aller Anweisungen kann erwartet werden, dass die Verfahren zu korrekten Ergebnissen führen und nur dann, – aber dann auch möglichst zuverlässig – eine Erkrankung oder eine Schwangerschaft anzeigen, wenn sie tatsächlich vorliegt (Krumm, Schmidt-Atzert & Amelang, 2021, S. 41-42).
In der pädagogisch-psychologischen Fachsprache versteht man unter einem Test eine Messmethode, bei der durch die Präsentation bestimmter Reize eine Verhaltensstichprobe von einer zu testenden Person gewonnen, analysiert und bewertet wird, um Aussagen über eine latente Fähigkeit oder Eigenschaft dieser Person machen zu können, die nicht direkt beobachtet werden kann – z. B. Rechenkompetenz, Leistungsmotivation oder Schulangst. Die Reize und wie sie zu präsentieren sind werden vorgegeben, das können z. B. Aufgaben sein, die zu lösen sind; Fragen, die zu beantworten sind oder Bilder, die zu deuten sind. Die Reaktionen der zu testenden Person werden beobachtet und protokolliert und im Hinblick auf die Ausprägung der latenten Fähigkeit oder Eigenschaft interpretiert, die gemessen werden soll. Die Anzahl und Qualität der Lösungen von Rechenaufgaben werden z. B. interpretiert als Indikatoren für Rechenkompetenz, die Antworten auf Fragen zur persönlichen Leistungsbereitschaft als Indikatoren für Leistungsmotivation oder die Interpretation von Bildern, die Kinder in typischen Unterrichtssituationen zeigen, wird nach Hinweisen auf Schulangst analysiert. Damit die individuellen Ergebnisse eingeordnet werden können, stellen die Autorinnen und Autoren von Tests sorgfältige Vergleichsdaten aus größeren Personengruppen zur Verfügung, damit die Ergebnisse nicht über- oder unterbewertet werden (Tröster, 2019, S. 58-60).
Wenn ein Test zur Prüfung und Optimierung von Voraussetzungen, Methoden oder Ergebnissen von Lehr- und Lernprozessen konstruiert und angewendet wird, handelt es sich um einen pädagogischen Test (Ingenkamp & Lissmann, 2008, S. 13). Solche Tests stellen neben dem diagnostischen Interview und der Verhaltensbeobachtung die drei zentralen Methoden der pädagogischen Diagnostik dar.
Damit ein diagnostisches Verfahren als pädagogischer Test gelten kann, muss es drei zentrale Bedingungen erfüllen (Krumm, Schmidt-Atzert & Amelang, 2021, S. 42-43):
Messgegenstand: Das Verfahren muss eine oder mehrere latente Fähigkeiten oder Eigenschaften messen, die explizit definiert und die pädagogisch bedeutsam sind.
Datenintegrität: Das Verfahren muss eine kontrollierte und nachvollziehbare Erhebung der diagnostischen Daten gewährleisten.
Interpretationsobjektivität: Das Verfahren muss geprüfte und zuverlässige Vergleichsdaten über Normalverhalten bzw. Standardzustände anbieten, die eine einheitlich vergleichende und nachvollziehbare Beurteilung individuell erzielter Testergebnisse erlauben.
Die Klärung des Messgegenstandes wird beispielhaft in den Abschnitten zur Schulleistungsmessung und zur Intelligenzmessung betrachtet. Bei der Sicherung der Datenintegrität ist die Standardisierung der Testbedingungen von instrumenteller Wichtigkeit, die im folgenden Abschnitt mit Blick auf die so genannten Testgütekriterien behandelt wird, bevor abschließend die Normierung eines Testes als Mittel der Sicherung von Interpretationsobjektivität beleuchtet wird.
Welche Bedeutung hat die Standardisierung der Testbedingungen?
Ein diagnostisches Interview will gut vorbereitet sein, ein diagnostisch aufschlussreiches Gespräch kann durchaus spontan und ungeplant stattfinden, eine Verhaltensbeobachtung kann im Alltag anfallende, auffällige Ereignisse dokumentieren. Ein pädagogischer Test hingegen verlangt grundsätzlich Planung und sorgfältige Vorbereitung. Nur dann, wenn die Reaktionen der zu testenden Personen auf die Aufgaben und Fragen eines Tests unter kontrollierten Bedingungen und in immer gleicher Weise evoziert, protokolliert und interpretiert werden, können diese miteinander und mit Normdaten verglichen werden. Das Mittel der Wahl ist die Standardisierung, das ist die verbindliche „Festlegung der Bedingungen, unter denen ein Test durchgeführt, ausgewertet und interpretiert wird“ (Tröster, 2019, S. 59).
-
Es wird vorgegeben, ob ein Test als Einzel- oder Gruppentest durchgeführt wird, wie lange die Testaufgaben bearbeitet werden dürfen und ob und nach wie vielen fehlerhaften Lösungen ein Test vorzeitig beendet wird.
-
Für jede Aufgabe sind die Instruktionen, eventuell vorzulegende Materialien und das Antwortformat vorgegeben, ebenso die Anzahl, Reihenfolge und die Art der Testaufgaben, die Bearbeitungszeiten, erlaubte Hilfsmittel und eventuell zusätzliche Erläuterungen zu einzelnen Aufgaben.
-
Die Protokollierung der Antworten ist einheitlich gestaltet, ebenso die Regeln zu deren Analyse und Interpretation im Vergleich zu Normwerten.
Eine Standardisierung der Testdurchführung schränkt die Interaktion zwischen der Person, die einen Test administriert und der Person, die einen Test absolviert, zwar erheblich ein, aber sie ist im Hinblick auf die Datenintegrität unverzichtbar. Könnten die Personen, die einen Test anwenden, die Interaktion mit den zu testenden Personen frei gestalten, die Aufgabenstellungen individuell erklären, über zusätzliche Erklärungen und Bearbeitungszeiten frei entscheiden und verbale Antworten ohne Vorgaben nach eigenem Ermessen auswerten, würden diese Unterschiede in die Testergebnisse eingehen und diese erheblich beeinflussen. Die Ergebnisse wären nicht mehr objektiv, sondern subjektiv – d. h. sie wären stark beeinflusst von den individuell sehr unterschiedlichen Handlungen der Untersucherinnen und Untersucher.
Objektivität, Reliabilität und Validität als zentrale Testgütekriterien
Objektivität ist das erste zentrale Gütekriterium eines Tests, der die Ausprägung einer Fähigkeit oder Eigenschaft einer zu testenden Person möglichst unverstellt messen soll. „Ein Test ist dann objektiv,“ schreibt Tröster (2019, S. 68), „wenn seine Ergebnisse unabhängig von der Person der Untersucherin oder des Untersuchers und von den Durchführungsbedingungen sind“. Objektivität betrifft drei Bereiche, die Durchführung eines Testes, seine Auswertung und die Interpretation der Testergebnisse. Testdurchführungsobjektivität wird, wie gezeigt, durch eine weitgehende Standardisierung der Instruktionen, Aufgaben und Materialien angestrebt. Testauswertungsobjektivität wird durch die Vorgabe von Musterlösungen oder Hinweisen zur differenziellen Bewertung komplexer Lösungen angestrebt. Zur Sicherung der Interpretationsobjektivität werden Vergleichsdaten bereitgestellt und Hinweise zu deren Verwendung gegeben – dazu können Sie im Abschnitt Testnormen zur Sicherung der Interpretationsobjektivität (s. u.) mehr erfahren.
Reliabilität ist das zweite zentrale Gütekriterium eines Tests. Es bezeichnet den Grad der Genauigkeit, mit der ein Test die Fähigkeit oder Eigenschaft misst, die er messen soll (Tröster, 2019, S. 74). Die Reliabilität hängt mit der Objektivität zusammen, denn wenn ein Testergebnis durch wechselnde Durchführungsbedingungen oder durch subjektive Entscheidungen des Untersuchers oder der Untersucherin beeinflusst wird, kann es nicht zuverlässig sein. Da keine pädagogisch-psychologische Testung völlig frei von Fehlern sein kann, wird die Reliabilität eines Testes in der Entwicklungsphase mit statistischen Verfahren geschätzt, indem z. B. zwei Hälften oder zwei Parallelformen eines Testes an die gleichen Personen (Testhalbierungsreliabilität, Paralleltest-Reliabilität) oder ein und derselbe Test wiederholt an die gleichen Personen gegeben wird (Retest-Reliabilität). Je ähnlicher die empirischen Ergebnisse ausfallen, desto genauer und zuverlässiger misst der Test.
Validität ist das dritte und wichtigste Gütekriterium. Sie bezeichnet die inhaltliche Gültigkeit eines Tests, definiert als der Grad, mit dem ein Test die Fähigkeit oder das Merkmal misst, das er messen soll (Tröster, 2019, S. 79). Nur wenn ein Test objektiv und reliabel misst, können die Ergebnisse valide sein, denn wenn sie subjektiv zustande kommen und wenig zuverlässig sind, kann man nicht wissen, was sie inhaltlich bedeuten. Andererseits kann ein Test zwar objektiv und reliabel messen und dennoch lassen sich die Ergebnisse nicht pädagogisch sinnvoll interpretieren – es muss nachgewiesen werden, dass sie wirklich gute Indikatoren für die zu diagnostizierenden Fähigkeiten oder Merkmale sind. Zu diesem Zwecke gibt man einen Test, z. B. einen Rechtschreibtest, in der Entwicklungsphase an eine größere Gruppe von Personen und lässt sie danach einen bislang bewährten Rechtschreibtest bearbeiten (Konkurrente Validität) oder umfangreiche Diktate schreiben (Kriteriumsvalidität). Je ähnlicher die Ergebnisse ausfallen, desto gültiger misst der Test.
Testnormen zur Sicherung der Interpretationsobjektivität
Wenn Testergebnisse objektiv, reliabel und valide ermittelt werden, müssen sie noch korrekt ausgewertet und bewertet werden. Auswertung und Bewertung von Testergebnissen sollten ebenfalls möglichst objektiv erfolgen, d. h. unterschiedliche Untersuchende sollten bei einem Ergebnis zu den gleichen diagnostischen Schlüssen gelangen.
Die objektive Auswertung von Testprotokollen kann durch die Vorgabe von Musterlösungen oder Hinweisen zur differenziellen Bewertung komplexer Lösungen erleichtert werden, die mit einem Test bereitgestellt werden (Tröster, 2019, S. 70-72). Eine möglichst objektive Bewertung von Testergebnissen ist jedoch weitaus schwieriger zu bewerkstelligen, denn ein und dasselbe Ergebnis kann positiv oder weniger positiv bewertet werden. Es kommt darauf an, auf welche Vergleichsdaten sich die Bewertung stützt (Tröster, 2019, S. 98-100), wie das folgende Beispiel zeigt:
Wenn ein Testergebnis besagt, dass von 20 Additionsaufgaben mit Überschreitung des Zehners im Zahlenraum bis 100 elf korrekt gerechnet wurden, so kann dieses Ergebnis ohne weitere Kenntnisse über ihr Zustandekommen nicht beurteilt werden. Es kann als ziemlich gutes oder ausgesprochen gutes Ergebnis für ein Kind im 2. Schuljahr bewertet werden, während es für ein Kind im 4. Schuljahr vermutlich als schwaches oder sogar unzureichendes Ergebnis bewertet würde. Aber selbst im 4. Schuljahr kann die Bewertung unterschiedlich ausfallen: Wenn die Lehrkraft berücksichtigt, wie mühsam bzw. erfolgreich ein Kind in der Vergangenheit gelernt hat, wird sie bei bislang deutlich schwächeren Leistungen für die elf korrekten Lösungen eine individuell positive Rückmeldung geben, bei zuvor besseren Leistungen wird sie dem Kind den relativen Leistungsabfall rückmelden.
Da ein Testergebnis allein und für sich genommen wenig aussagekräftig ist, werden Bezugsnormen benötigt, an denen man sich orientieren kann. Im oben gezeigten Beispiel könnten das Daten zu den durchschnittlichen Rechenleistungen altersgleicher Kinder, zu den zu erwartenden Leistungen im 2. bzw. 4. Schuljahr oder Daten über die Entwicklung der individuellen Rechenleistungen des getesteten Kindes sein. Wir werden in diesem Abschnitt die drei Arten von pädagogisch relevanten Bezugsnormen vergleichend vorstellen und in den folgenden Abschnitten zur Intelligenz- und Schulleistungsmessung zeigen, dass bei den Verfahren zur Feststellung sonderpädagogischen Unterstützungsbedarfs bislang vor allem eine Art von Tests und Bezugsnormen Verwendung findet: der soziale Vergleich bei einmaliger Testung.
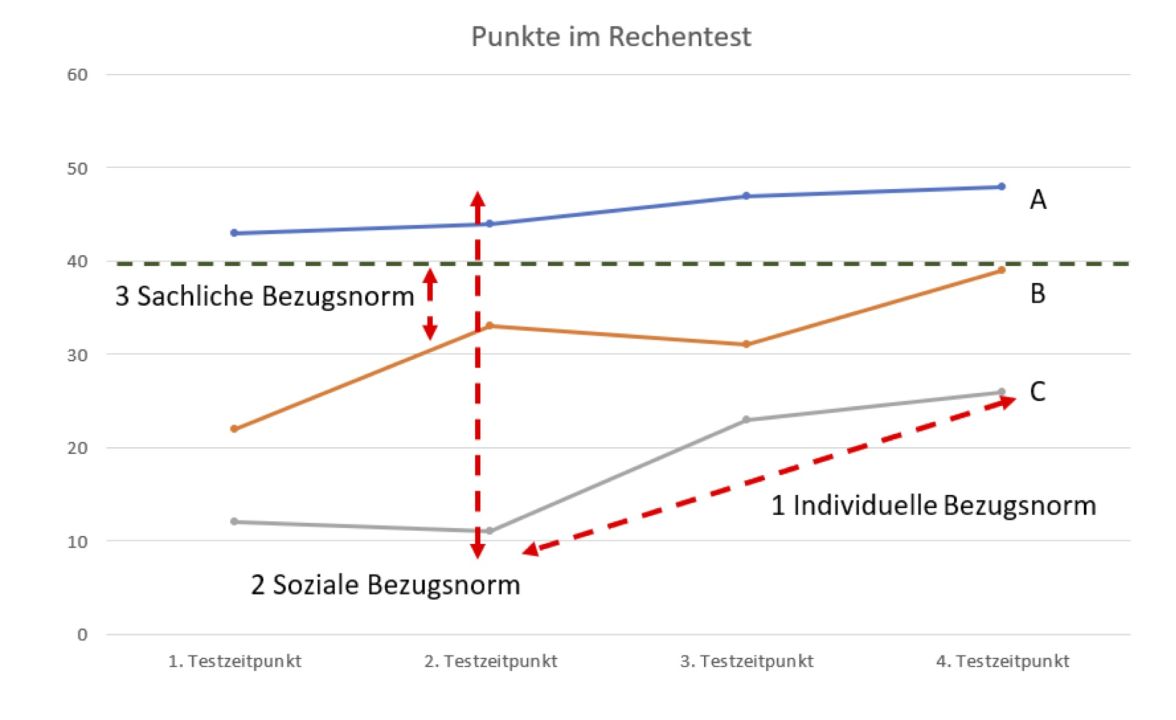
Abbildung 1: Vergleichsperspektiven bei drei Bezugsnormen zur Leistungsbewertung (nach Rheinberg, 2001, S. 62)
Bezugsnormen entstehen durch Vergleiche. Die Abbildung soll helfen, die Vor- und Nachteile von drei Perspektiven zu diskutieren, die man bei der pädagogischen Bewertung von Testergebnissen einnehmen kann. Sie zeigt in Anlehnung an Rheinberg (2001, S. 62) die Entwicklung der Rechenleistungen, gemessen als erreichte Punkte in einem Rechentest, für die drei fiktiven Lernenden A, B und C bei viermaliger Testung über einen gewissen Zeitraum hinweg.
-
Wenn man die drei Lernkurven vergleichend betrachtet, wird deutlich, dass die drei Kinder zum ersten Testzeitpunkt auf unterschiedlichen Niveaus beginnen und dass die Rangfolge im zeitlichen Verlauf erhalten bleibt: A vor B und B vor C.
-
Wenn man die individuelle Entwicklung von A, B und C im zeitlichen Verlauf betrachtet, stellt man fest, dass sich alle drei Lernenden verbessern, denn ihre Lernkurven zeigen zwar Schwankungen, aber auch einen positiv ansteigenden Trend.
-
Wenn man die Differenzen zwischen dem erstem und zweitem Testzeitpunkt betrachtet, wird deutlich, dass die drei Kinder unterschiedlich schnell lernen. Kind C lernt schneller dazu als Kind B und dieses wiederum schneller als Kind A.
Wie sind die Entwicklungsverläufe zu bewerten? Es kommt auf die Vergleichsperspektive an, und diese kann individuell, sozial oder sachlich ausgerichtet sein.
Bei individueller Bezugsnorm orientiert sich die Beurteilung einer aktuell gezeigten Leistung an den im zeitlichen Verlauf zuvor gezeigten individuellen Leistungen des Kindes (Pfeil 1). Dies ist besonders für Lernende mit relativ zu anderen Lernenden schwachen Leistungen förderlich, denn sie werden nicht mit anderen verglichen, sondern an ihren eigenen Leistungen gemessen. Eine individuelle Orientierung hat zwei pädagogische Vorteile: Der Erfolg individueller Anstrengung kann positiv gewürdigt werden, auch wenn die gezeigte Leistung im Vergleich zur Leistung anderer Kinder eher schwach ist und bleibt, und es kommen durch die individuelle Betrachtung im zeitlichen Verlauf auch relativ kleine Lern- und Entwicklungsfortschritte zeitnah in den Blick. Die individuelle Bezugsnorm macht es also möglich, auch Lernenden wie Schüler C ermutigende Rückmeldung zu geben, aber sie blendet den sozialen und den sachlichen Vergleich aus. Im Extremfall kann bei ausschließlich individueller Bezugsnorm bei allen Lernenden einer Lerngruppe der richtige Eindruck entstehen, dass alle dazulernen können, aber niemand wird so recht wissen, in welchen Bereichen die eigenen Stärken oder Schwächen liegen (Rheinberg, 2001, S. 65).
Bei sozialer Bezugsnorm orientiert sich die Beurteilung von gemessenen Leistungen an den Leistungen ähnlicher Personen, bei Kindern und Jugendlichen vor allem altersgleicher Personen (Pfeil 2). Das ist vor allem dann sinnvoll, wenn das Ziel darin besteht, Selektionsentscheidungen zu treffen, z. B. die besten Lernenden mit besonderen Interessen und Begabungen zu identifizieren oder die schwächsten Lernenden mit Unterstützungsbedarf, um ihnen Hilfen zukommen zu lassen. Lehrkräfte orientieren sich beim sozialen Vergleich in der Regel an der Lerngruppe, aber das ist problematisch, denn ein solcher Vergleich kann zwar klassenintern geführt werden, aber er berücksichtigt nicht, wie hoch oder niedrig das Niveau in der Lerngruppe im Vergleich zu anderen Lerngruppen an anderen Schulen ist. Aus diesem Grund erstellen die Autorinnen und Autoren von Testverfahren umfangreiche statistische Tabellen, die an repräsentativen Personenstichproben gewonnen wurden und die differenzierte Normdaten anbieten, wie in den folgenden Abschnitten zur Schulleistungs- und Intelligenzmessung gezeigt wird.
Durch statistische Normen wird der soziale Vergleich auf eine relativ objektive Basis gestellt, aber es bleiben zwei pädagogisch problematische Konsequenzen, die sich ungünstig auf die Lern- und Leistungsmotivation auswirken, und zwar grundsätzlich für alle Lernenden, aber nachweislich besonders für Lernende mit relativ schwachen Leistungen (Rheinberg, 2001, S. 64):
-
Weil bei der sozialen Bezugsnorm nur die Unterschiede zwischen den Lernenden entscheiden, wird ausgeblendet, dass alle Lernenden dazulernen und sich weiterentwickeln (vgl. Abbildung). Schüler C lernt relativ zu seiner Ausgangslage ähnlich erfolgreich dazu wie die Schüler A und B, aber er bekommt im sozialen Vergleich gleichbleibend schwache Leistungen bescheinigt, seine individuellen Lernzuwächse werden nicht sichtbar.
-
Weil bei der sozialen Bezugsnorm nur die Unterschiede zwischen den Lernenden entscheiden, kann Schüler C sich nur dann verbessern, wenn er erfolgreicher lernt als Schüler B. Lernerfolg wird nur dann deutlich, wenn es dem Schüler gelingt, in der Rangfolge aufzusteigen, und solche Zuwächse sind gerade bei schwachen Lernenden nur selten zu beobachten.
Bei sachlicher Bezugsnorm orientiert sich die Beurteilung von gemessenen Leistungen an inhaltlich umschriebenen Standards (Pfeile 3), z. B. Mindestkompetenzen oder Kompetenzstufen, im Bereich von Schule und Unterricht im Idealfall bezogen auf Bildungsstandards (Blum et al., 2006; Walter et al., 2008), Lehrpläne und Curricula (Curriculare Validität). Auf diese Weise geraten diagnostisch relevante Informationen in den Blick, die bei individueller und sozialer Bezugsnorm nicht dargestellt werden können. Rheinberg schreibt dazu (2001, S. 66):
Ob alle Schüler einer Klasse viel mehr oder viel weniger können, als das vom Lehrplan gewünscht ist, bleibt sowohl beim sozialen Vergleich zwischen verschiedenen Schülern, als auch beim individuellen Vergleich mit vorherigen Resultaten desselben Schülers unsichtbar. Das kann man erst sehen, wenn man die vorliegenden Resultate mit klaren inhaltlich bestimmten Maßstäben, also mit sachlichen Bezugsnormen vergleicht.
Was ist zu tun?
Jede der drei diskutierten Vergleichsperspektiven hat ihre Stärken und ihre „Blinden Flecken“ (Rheinberg, 2001, S. 65; Jungjohann & Gebhardt, 2022):
-
Die individuelle Bezugsnorm betont die Lernentwicklung des/der Einzelnen und erlaubt, auch Lernenden wie C ermutigende Rückmeldung zu geben, aber sie blendet den sozialen und den sachlichen Vergleich aus.
-
Die soziale Bezugsnorm betont die Leistungsunterschiede zwischen den Lernenden und erlaubt deren relative Beurteilung, aber sie blendet die individuelle Lernentwicklung und den sachlichen Vergleich aus.
-
Die sachliche Bezugsnorm betont die Bedeutung der individuell gezeigten Leistung eines/einer Lernenden in Relation zu inhaltlich definierten Kompetenzerwartungen, aber sie sagt wenig über die individuelle Lernentwicklung und über deren Ergebnisse relativ zu anderen Lernenden aus.
Wer das Testergebnis eines Kindes pädagogisch beurteilen möchte, wird nicht nur das „reine“ Testergebnis beachten, sondern darüber hinaus auf weitere relevante Informationen zurückgreifen, z. B. auf die bisherige Entwicklung des Kindes, seine familiäre und soziale Situation, seine Stellung in der Lerngruppe, die Ergebnisse aus diagnostischen Gesprächen oder Verhaltensbeobachtungen im Unterricht (Tröster, 2019, S. 71). Angesichts der pädagogischen Vor- und Nachteile der drei diskutierten Vergleichsperspektiven kann man zu dem Schluss gelangen, dass in Schule und Unterricht je nach diagnostischer Zielsetzung die Bezugsnormen zu wählen sind und dass oft diagnostische Verfahren mit kombinierte Vergleichsdaten sinnvoll sein dürften. Es gibt einige erste Testverfahren, die als Lernentwicklungstests oder als curricular orientierte Kompetenztests angelegt sind und weitere Instrumente befinden sich in der Entwicklung (Gebhardt, Jungjohann & Schurig, 2021), aber ihre Verwendung im Rahmen eines AO-SF-Verfahrens stellt bislang die seltene Ausnahme dar. Im Rahmen des AO-SF kommen sehr häufig Schulleistungstest und Intelligenztests zum Einsatz. Da es im Rahmen des Verfahrens vor allem um Selektionsentscheidungen geht, sollte es nicht verwundern, dass zu deren Normierung nach wie vor interindividuell vergleichende Daten angeboten werden.

